近频繁调用大模型 API,发现绕不开 Token 这个概念——API 定价按 Token 收费、上下文窗口用 Token 衡量、输出长度也受 Token 限制。整理一下 Token 到底是什么,顺便写个脚本来计算。
什么是 Token?
Token 是大语言模型处理文本的最小单位。
它不是”字”,也不是”词”,而是介于两者之间的语言碎片。模型在训练和推理时,看到的不是原始字符串,而是一段被切分好的 Token 序列。
举个直观的例子:
"Hello, world!" → ['Hello', ',', ' world', '!'] # 4 个 Token
"大语言模型" → ['大', '语言', '模型'] # 3 个 Token这个切分过程叫做 tokenization (分词),负责切分的工具叫做 tokenizer (分词器)。
Token 的生成原理
现在主流的大模型基本都用 BPE(Byte Pair Encoding,字节对编码) 算法来构建词表和切分文本。
BPE 的核心思路很简单,用一句话概括就是:从字符出发,不断合并高频相邻字节对,直到词表达到目标大小。
以英文为例,训练过程大致如下:
初始词表:所有字符(a-z、0-9、标点等) 统计语料中所有相邻字节对的出现频次 合并出现最频繁的字节对,生成新的 Token 重复步骤 2-3,直到词表大小达到预设值(GPT-4 的词表约有 10 万个 Token)
以 “low lower newest” 为例,lo 出现 2 次,ow 出现 2 次,ne 出现 2 次……不断合并高频对,最终 “low” 就可能成为一个独立的 Token,而 “newer” 可能被切成 ['new', 'er']。
不同模型用不同的 Tokenizer:
- GPT 系列 / DeepSeek
:用 tiktoken,编码方案是cl100k_base(GPT-4)或o200k_base(GPT-4o) - Llama / Qwen 等开源模型
:通常用 SentencePiece或基于HuggingFace tokenizers构建
同一段文字,用不同模型的 Tokenizer 切出来的结果不一样,Token 数量也会有差异。
中英文 Token 差异
为什么总感觉中文字符的 Token 比英文字符的 Token 贵呢,包括 DeepSeek 里面的说明也是
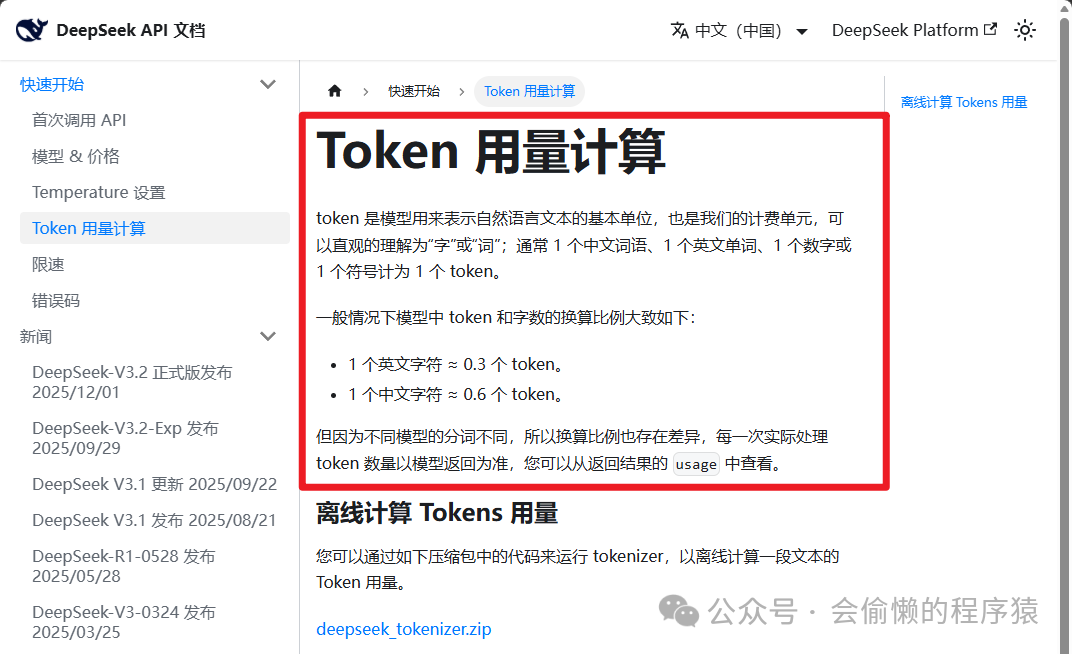
实际上 BPE 不区分语言,只认频率——训练数据里出现越频繁的字节组合,越容易被合并成单个 Token。英文和中文遵循完全相同的规则,差别只在于训练语料的分布:
英文语料历来占主导,大量英文词和词组都被充分合并,1 个 Token 大约对应 0.75 个单词 中文语料相对少的早期模型,中文字符合并程度低,很多字只能单独成 Token;随着语料增加和词表扩大(如 GPT-4o 的 20 万词表),常用中文词组如”大语言模型”、”人工智能”已经可以合并成 1~2 个 Token 生僻字不管哪种语言,只要频率极低,都会被拆成多个字节 Token
数字和代码也有类似情况:连续的数字串(如 12345)往往会被切成多个 Token,代码中的缩进空格也会占用 Token,所以对于开发人员而言,总感觉 Token 在燃烧。
Token 与 API 费用
各大模型 API 的计费方式基本统一:输入 Token + 输出 Token 分开计费,输出通常比输入贵。
以 DeepSeek 为例:
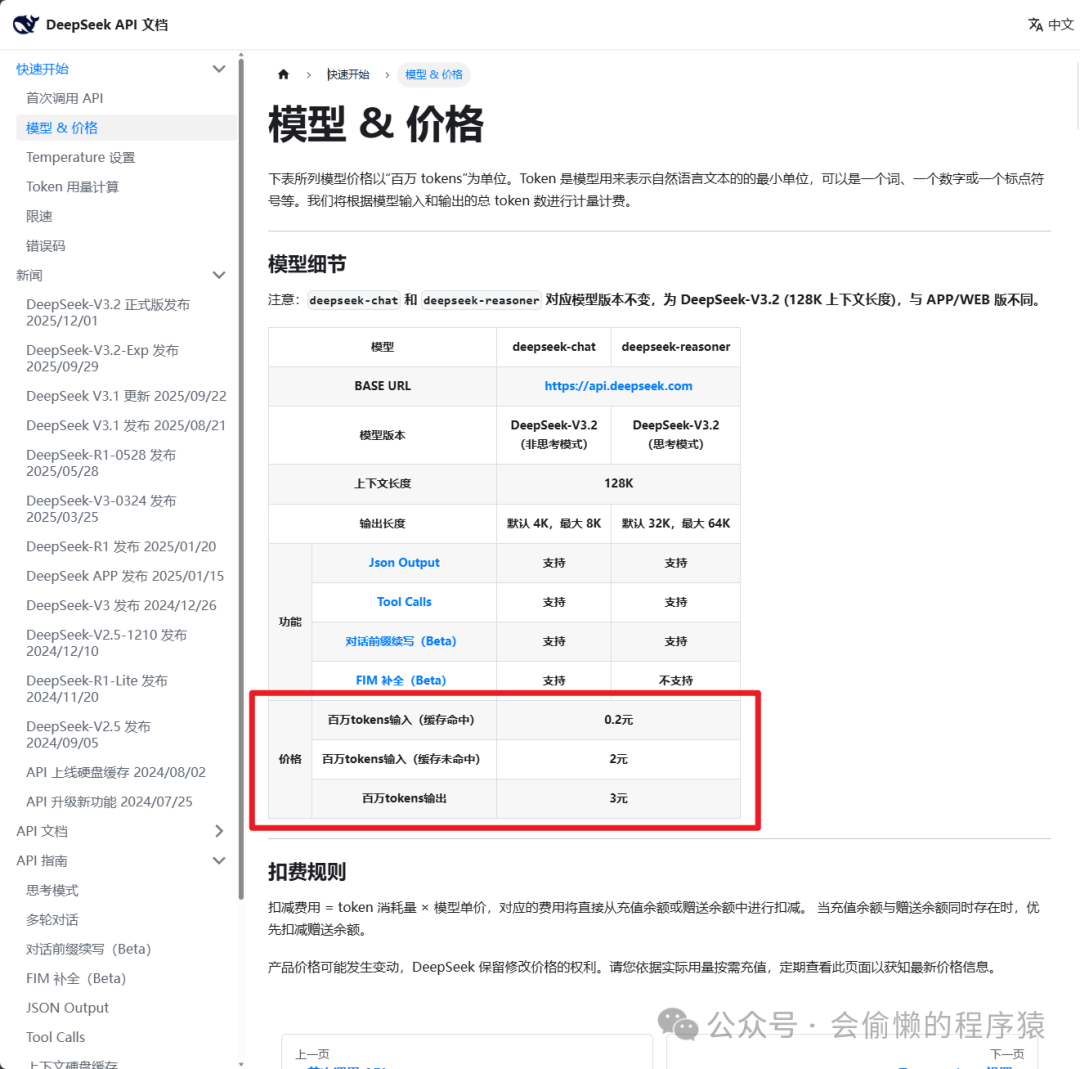
除了费用,Token 还决定了上下文窗口(context window)。比如某模型最大支持 128K context,意味着一次对话(包括历史消息 + 当前输入 + 输出)不能超过 128K 个 Token。超出之后,模型就会”遗忘”早期的对话内容。
所以提前计算 Token 数量,对控制成本和避免截断都很有实际意义。
用 Python 计算 Token 数量
tiktoken 是 OpenAI 开源的分词库,本地运行,不需要联网,安装后即可直接使用。
pip install tiktokenimport tiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
texts = ["Hello, world!", "你好,世界!", "Large Language Model", "大语言模型"]
for text in texts:
tokens = enc.encode(text)
print(f"'{text}' => {len(tokens)} tokens")运行结果:

也可以把每个 Token 的切分边界打印出来,看得更直观:
importtiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
def visualize_tokens(text: str):
tokens = enc.encode(text)
decoded = [enc.decode([t]) fortintokens]
print(f"'{text}' => {len(tokens)} tokens")
print(" | ".join(repr(t) fortindecoded))
print()
visualize_tokens("Hello, 你好!")
visualize_tokens("ChatGPT 大语言模型")运行结果:

注意:tiktoken 使用的是 GPT-4 的编码方案,用来做估算足够,精确计费可以参考模型 API 返回的 usage 字段。
总结
Token 是大模型处理文本的基本单元,本质上是 BPE 算法训练出来的子词片段。理解 Token 对实际开发很有帮助:
中文比英文更消耗 Token,同样的语义用中文表达成本更高 API 按输入和输出 Token 分别计费,提前估算可以控制成本 上下文窗口本质上是 Token 数量的上限,超出会导致早期内容被截断






